Blog | Registrant Classification: A Predictive Model
Problem Overview
When registering a .ie domain, the registrant or domain holder must specify whether they represent a Company, a Charity, or Other, as the registrant verification process varies based on this information. Each category follows a different registration process. However, there is a risk that registrants may choose a category based on convenience or to bypass certain requirements, which can impact the accuracy of these classifications.
This makes it essential to validate registrant data, particularly with the introduction of the EU NIS2 regulations, which stress the need for precise and consistent data collection.
To address these challenges, we aim to implement a model that derives the registrant type directly from the registrant’s name, rather than relying solely on self-declared categories. Additionally, we strive to expand the classification system to include new categories such as Statutory/Governing Bodies, Educational Institutions, Community/Union/Charity, and Sports Clubs.
This approach will help ensure more accurate classification and identify cases where registrants may initially declare one type but later switch to another, offering deeper insights into registration trends.

Proposed Solution
To bring this vision to life, we’ve developed a machine-learning classification model designed specifically to precisely categorise domain registrants. This model serves two critical functions:
-
Validating Existing Data: Ensuring that current registrant classifications are accurate and reliable.
-
Predicting Future Registrant Categories: Automating the classification of new domain registrations for a smoother process.
With this solution, we address the immediate need for data validation and streamline the registrant classification process, significantly reducing manual effort while enhancing compliance with regulatory requirements.
From Concept to Code: Building Our Predictive Model
Before delving into the specifics of the model architecture and enhancements, it’s important to outline the various stages of the project. Initially, the 6-label classification (Company, Natural Person, Statutory/Governing Body, Educational Institution, Community/Union/Charity, Sports Club) did not deliver the desired outcomes, prompting the implementation of oversampling and data preprocessing techniques. This led to the development of a 5-label classification model, which showed promising results. Ultimately, we found that a 3-label classification (Company, Natural Person, Others) yielded the best performance and aligned closely with our intended use case for the model. However, the architecture is designed to allow for easy adaptation back to 5-label classification if necessary.
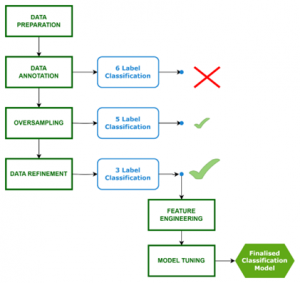
Data Preparation and Pre-processing
The development of the proposed machine learning model relies on a labelled dataset for training. The original .IE registrant database contains approximately 160,000 entries, with each record comprising the registrant’s name and type. For model training purposes, an initial subset of 5,000 registrants was selected.
Dataset Overview
This dataset includes three key fields: ID, Registrant Name, and Registrant Type. However, only the Registrant Name is relevant for model development, as the assigned IDs lacks categorical significance and the Registrant Type field is considered unreliable—both due to potential inaccuracies in the existing data and the absence of detailed labels for detailed classification. Following extensive data preparation and annotation, the training dataset was expanded to 10,419 samples by incorporating additional data.
Data Annotation
We used the Prodigy tool to annotate data for the registrant classification model training. Prodigy streamlines the process with features such as a web-based interface, pre-built workflows for various tasks, data inspection and cleaning tools, seamless integration with SpaCy, and support for rule-based systems alongside statistical models.
After setting up Prodigy, we executed built-in recipes to create a manual annotation interface and export annotations in the desired format while utilizing pretrained SpaCy models to evaluate dataset quality. The annotation process involved two rounds: the first focused on categorizing samples into predefined labels along with a “Don’t Know” class for uncertain cases, while the second aimed to address missed annotations and reduce the “Don’t Know” category. Prodigy’s review recipe played a crucial role in comparing both rounds, enabling us to correct inconsistencies and finalize the annotated dataset.
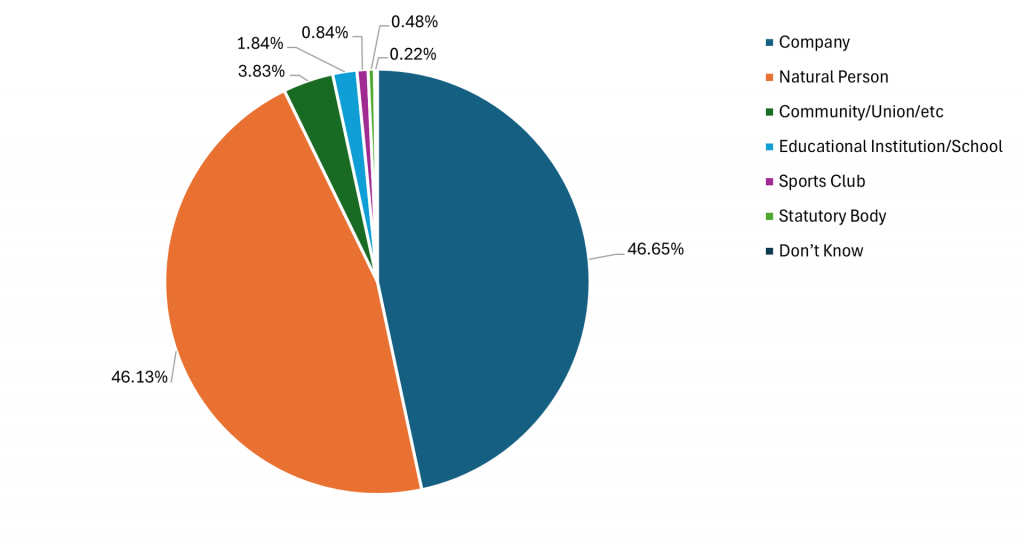
After completing the annotation process, we analyzed the class distribution of the 4,990 selected samples. As illustrated in the accompanying chart, our annotated dataset revealed a significant imbalance:
-
The Company and Natural Person classes together accounted for a staggering 93% of the total data.
-
To put this into perspective, the Company class had nearly 100 times more samples than the Statutory Body class.
This pronounced imbalance posed a risk of biasing the model toward the dominant classes, potentially hindering its ability to accurately identify categories with fewer training samples. Addressing this class imbalance was essential before we could confidently proceed with model training.
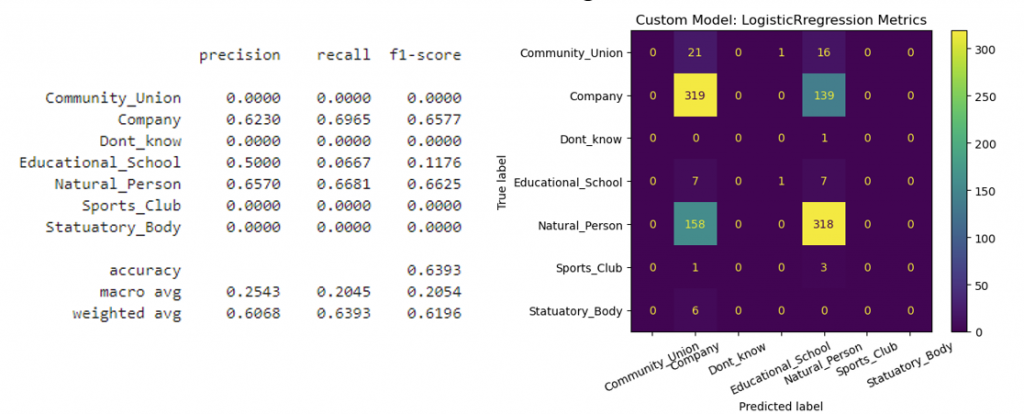
This inference was further supported by an analysis of evaluation metrics from two sources: a custom baseline model built with scikit-learn and metrics from the Prodigy framework integrated with Spacy.
The metrics presented here illustrate the performance of the baseline model trained on the annotated dataset.
-
Although the overall accuracy reached 63.93%, the scores for the minority classes were essentially zero.
-
Furthermore, the confusion matrix indicated that the model did not predict any instances from these minority classes, demonstrating a clear bias toward the Company and Natural Person categories.
This underlines the urgent need to address class imbalance to enhance model performance.
Managing Imbalanced Classes
Effectively handling class imbalance was essential for building a high-performance model. To address this, we employed two methods to identify additional samples from the pool of registrants in the .ie database, aiming to achieve a more uniformly represented dataset.
-
Semantic Similarity using SBERT embeddings –
Our initial strategy utilized Sentence-BERT embeddings to measure cosine similarity among samples across different classes. The aim was to set a similarity threshold for each class to query the database for additional samples. However, it quickly became clear that the semantic similarities, both within and across classes, were not distinct enough to yield useful results. This limitation rendered the approach ineffective for augmenting the training dataset.
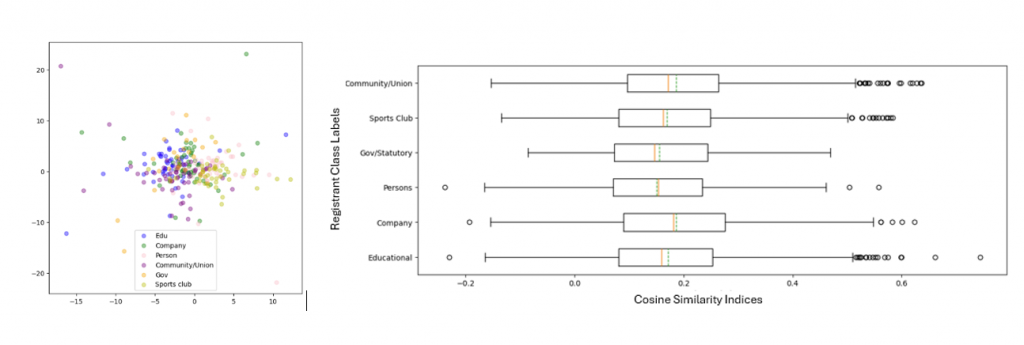
The first image below illustrates that the embeddings were largely indistinguishable when visualized. The second image presents a box plot analysis for one of the classes, showcasing the distribution of similarity indices between the class in question and other classes. This evaluation further indicated that a definitive cosine similarity index threshold could not be established, as the scores fell within similar ranges for samples across different classes.
-
Keyword Extraction and Matching
In light of the first approach’s limitations, we implemented an alternative method that focused on extracting commonly used keywords within each minority class. Through exploratory data analysis of the annotated training dataset, we identified the top and unique keywords for each class. We then searched the registrant database, which contains approximately 160,000 entries, for these keywords, successfully expanding our training dataset.
An example of the analysis conducted for Statutory/Governing bodies is illustrated below:
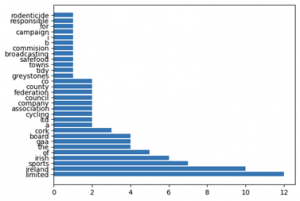
Further Data Refinement
Our keyword identification process successfully generated 9,685 new samples, but we encountered duplicates due to overlapping keywords—like “club,” which appeared in both Sports Club and Community/Union/Charity categories. This overlap required a comprehensive review and re-annotation using Microsoft Excel.
Distinguishing between Statutory/Governing Body and Community/Union/Charity samples was challenging, especially when registrants’ websites lacked clarity. In some cases, samples fit both categories, such as charities operated by governmental bodies. To simplify our dataset, we merged these two classes and excluded the newly identified Community/Union/Charity samples, resulting in a refined training dataset of 10,707 samples.
We also enhanced data quality by removing duplicates and irrelevant entries.
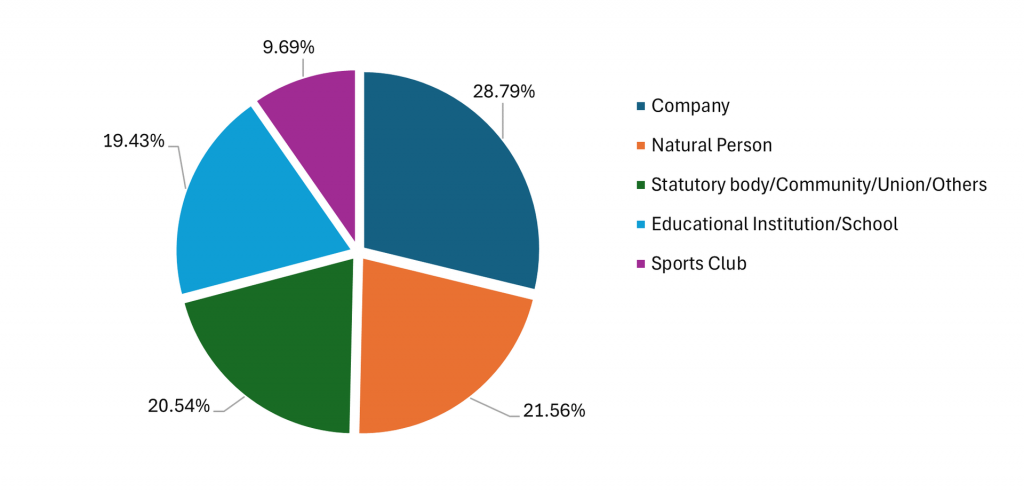
After these preprocessing steps, the training dataset was finalized at 10,419 samples. As illustrated in the accompanying pie chart, the training dataset is now more uniformly balanced and ready for model development
Additionally, the evaluation metrics from the earlier baseline custom pipeline were used to validate this refined dataset. The evaluation metrics shown here also demonstrate significant improvement across all classes, indicating that the data is prepared for the subsequent feature engineering and model enhancement stages.
Feature Engineering – The Secret Sauce for Model Success
The first step in building the classification model was generating meaningful features from the raw textual data, as raw text cannot directly serve as input to a machine learning model. To transform the text into something the model could process, we represented it as numerical vectors or embeddings. After experimenting with different approaches, we settled on a combination of TF-IDF and SBERT features to create the embeddings for the training model.
Term Frequency – Inverse Document Frequency: TF-IDF is a method used to convert textual word tokens into numerical features by examining the frequency of the text sequences. It is calculated as the product of Term Frequency and Inverse Document Frequency.
Sentence-BERT (SBERT): SentenceTransformers is a Python framework for text and image embeddings. It is a modification of the pretrained BERT network to derive semantically similar sentence embeddings.
To improve the effectiveness of feature generation and selection, we conducted several experimental analyses before finalizing our approach:
-
SBERT Model Selection: Initially, we used the SBERT pre-trained model ‘stsb-roberta-large’. However, after further research and testing, we switched to ‘all-distilroberta-v1’, a smaller, more computationally efficient model. This change helped streamline the process and improving accuracy.
-
Custom SBERT Transformer: Originally, embedding generation required a sequential process—first generating SBERT embeddings, then applying a TFIDF Transformer. To optimize this, we developed a custom SBERT Transformer Class that allows SBERT and TFIDF embeddings to be generated in parallel, concatenating the results at the end. This adjustment improved the efficiency of feature generation.
-
Feature Selection: We compared Principal Component Analysis (PCA) with Recursive Feature Elimination (RFE) to select relevant features from the generated embeddings. While both techniques aim to reduce dimensionality by ignoring irrelevant features, RFE proved computationally intensive and didn’t yield significant performance improvements. PCA offered slight performance gains but didn’t justify the computational overhead. As a result, we decided not to include either in the final pipeline.
These enhancements boosted the baseline model accuracy from 92% to 94.18% and reduced feature generation time by a few seconds. While this may seem modest, it becomes highly impactful when scaling up for real-world applications—such as predicting RANT classes for 160,000 domains in the .ie database.
Polishing the Model Performance: Optimizing and Evaluating Our Model
The final step in building the predictive model involved implementing a machine learning algorithm trained on the features generated in the previous step. The scikit-learn toolkit offers various packages to experiment with different classification algorithms, each providing functionalities for model fitting, training, and prediction. The training dataset was divided into an 80%-20% split for training and validation, respectively. The model was trained on the training set and evaluated on the validation set. Several classification algorithms were tested, followed by a comprehensive comparative analysis of the results. Details regarding the evaluation and comparison of the classification models can be found in the subsections below.
Cross-Validation and Hyperparameter Tuning
Cross-validation is one of the techniques to assess the performance of a predictive model. It includes resampling and sample splitting methods that use different portions of the data to test and train a model on different iterations, which is pictorically represented below. In our model, cross-validation is implemented by using a combination of Stratified KFold and GridSearchCV for hyperparameter tuning.
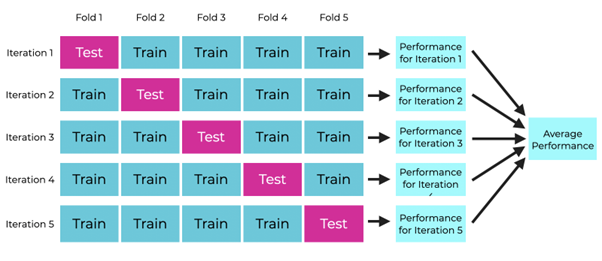
Cross-validation Explained. Source: sharpsightlabs.com
Evaluation Metrics for Model Performance Analysis
The metrics employed to quantitatively assess the results were –
-
Classification Metrics: Various metrics, including accuracy, precision, recall, and F1 score, were utilized to evaluate model performance. The F1 score, in particular, provides a balance between precision and recall, making it especially useful for our classification tasks.
-
Confusion Matrix: This tool was employed to visualize the model’s performance by summarizing true positives, true negatives, false positives, and false negatives, allowing for a clear assessment of the model’s strengths and weaknesses.
Overall, through these evaluation techniques, we identified the optimal configurations and metrics necessary for robust model performance in our classification tasks.
Discovering the Findings: Results, Challenges, Key Insights
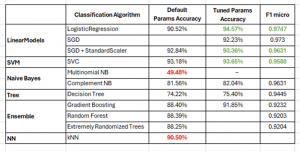
The table below presents the performance evaluation metrics from experiments comparing various classification algorithms, along with their hyperparameter-tuned results. Key observations include:
-
Linear models consistently delivered the best overall performance.
-
Some algorithms, such as SGDClassifier and Naive Bayes, required scaling, as they do not support sparse input features.
-
Naive Bayes models were further normalized, as the scaled feature embeddings needed to be positive for successful implementation.
-
Hyperparameter tuning was skipped for algorithms that showed insufficient results during preliminary testing.
-
The KNeighborsClassifier proved impractical, as its
.predict()function was excessively slow. This “lazy learner” approach memorizes the entire training dataset, making it unsuitable for real-time prediction of 160,000 registrants.
Final Revelations
Further analysis was conducted on the linear models with the feature enhancements mentioned earlier. The final insights derived were:
-
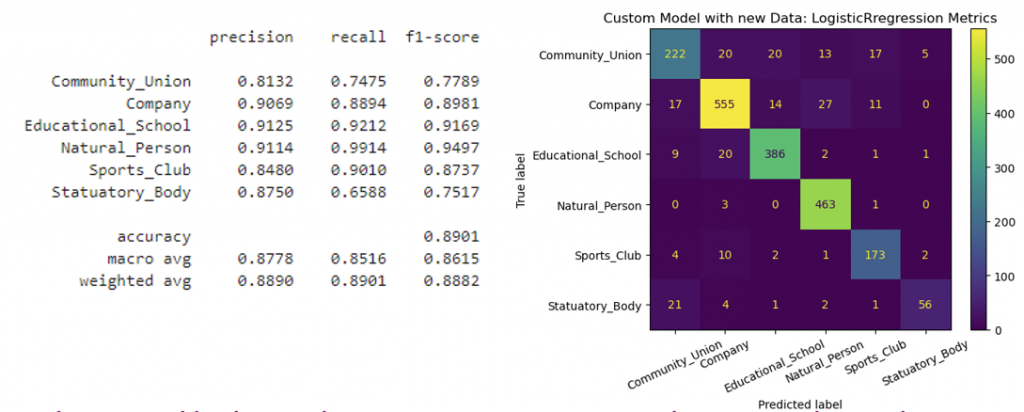
The Support Vector Classifier (SVC) algorithm yielded the most optimal model, achieving the highest overall accuracy, as well as the best micro-F1, recall, and precision scores for individual classes.
-
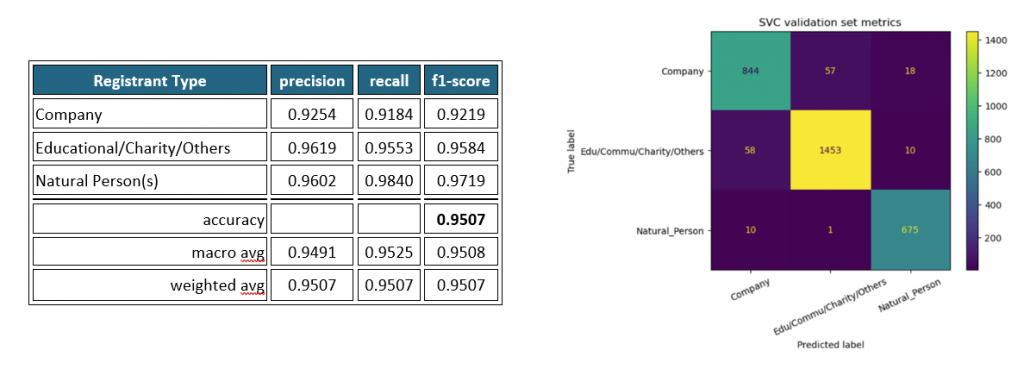
Validation results demonstrated an accuracy of 95.07% and a micro F1 score of 0.987.
-
The classification report and confusion matrix indicated fewer incorrect predictions, leading to the implementation of the finalized production code using scikit-learn’s SVC (
sklearn.SVC()) classifier.
Bringing the Model to Life: Production Deployment and Privacy Safeguards
Once we had the final model locked down, it was time to bring it into the real world. Using AWS S3 and SageMaker, we integrated the model into a production pipeline that not only powers real-time predictions but also keeps user privacy front and center. Let’s take a closer look at how this was done:
Real-Time Predictions via API:
By deploying the model, we generated a fully functional API endpoint. This allowed us to serve predictions on the fly, directly impacting how the system responds to incoming data. But ensuring privacy and security was the top priority.
Here’s how we tackled privacy during deployment:
-
Ironclad Data Security: All data lives securely within our AWS environment, where we’ve locked down access to specific users based on their roles. No unnecessary eyes on sensitive data, period.
-
Safe Data Prep: Before training even started, raw data was carefully prepared on our secure internal network. From there, it was uploaded to AWS S3, where further processing took place. Every step was secured.
-
Seamless SageMaker Integration: We used a private AWS SageMaker instance to train the model. It pulled data from S3, worked its magic, and stored the final model in a designated S3 bucket, all within a tightly controlled environment.
-
Abstraction for Ease & Security: One of the coolest things about SageMaker is how it abstracts all the heavy lifting. From data to code, everything gets simplified down to a consumable endpoint. No need to worry about the nitty-gritty, just plug it in and go! Here’s how it works:
-
Estimator Object: This fetched the trained model and spun up a production endpoint. Once live, anyone who needs to interact with the model can do so effortlessly.
-
Predictor Object: This makes the endpoint usable by passing custom inputs and generating predictions. It even handles input batching and feature generation in the background, keeping things smooth and hassle-free.
-
By focusing on seamless integration and data privacy, we’ve ensured that the entire system is as secure as it is efficient. The model is now ready for prime time, delivering real-time predictions while keeping sensitive data safe and sound.
Conclusion
Technical Summary
Through a series of experiments involving 6-label, 5-label, and finally 3-label classification models, we determined that the 3-label model offers the best performance and aligns closely with our future applications. Although the 5-label classification also showed promising results, the model has been designed to easily switch between 3 and 5 labels, ensuring flexibility for future needs.
The final model achieved an impressive accuracy of 95.07% and an F1-score of 0.987 on the validation set. It’s now successfully deployed in the AWS S3 and SageMaker environment, providing real-time predictions for registrant types. This deployment supports automatic model retraining, while ensuring that data security and privacy concerns are addressed at every stage.
Notably, during testing, the model processed predictions for approximately 8,000 registrants in just 30 seconds, demonstrating its speed and efficiency.
Impact and Future Work
The model classifies domain registrants as Company, Natural Person, or Others with 95.07% accuracy, using only the registrant’s name. For example, given the name “Mary Poppins”, the model would classify it as a Natural Person. Moving forward, this model will be instrumental in validating current registrant data and enhancing the precision of trend analyses for new registrations. By automating the prediction of registrant types, it will cut manual processing time from approximately 30 days to just a few seconds, greatly optimizing compliance efforts.
In the future, the model’s output could also be incorporated into other projects, such as NACE classification or domain renewal prediction, offering even broader applications and insights.
Access all blogs here
As the trusted national registry for over 330,000 domain names, .ie protects Ireland’s unique online identity and empowers people, communities and businesses connected with Ireland to thrive and prosper online. A positive driving force in Ireland’s digital economy, .ie serves as a profit for good organisation with a mission to elevate Ireland’s digital identity by providing the Irish online community with a trusted, resilient and accessible .ie internet domain. Working with strategic partners, .ie promotes and invests in digital adoption and advocacy initiatives – including the .ie Digital Town Blueprint and Awards for local towns, communities and SMEs. We provide data analytics and dashboards built by the .ie Xavier team to help with data-led decision-making for the public, registrars and policymakers. The organisation is designated as an Operator of Essential Services (OES) under the EU Cyber directive, and we fulfil a pivotal role in maintaining the security and reliability of part of Ireland’s digital infrastructure.